# 如何编程调用OpenAI的ChatGPT API接口
目录
# 前言
最近大火的ChatGPT提供了一系列API接口,可以调用多种模型进行对话,来进行
- 起草电子邮件或其他书面文件
- 编写代码
- 回答有关一组文件的问题
- 创建会话代理
- 为您的软件提供自然语言界面
- 一系列科目的导师
- 翻译语言
- 模拟视频游戏中的角色等等
# 准备
注册一个OpenAI账号,可参考:中国区注册OpenAI账号试用ChatGPT指南 (opens new window)
Python开发环境 Python >=3.7.1
# 获取开发KEY
打开https://platform.openai.com/account/api-keys (opens new window)
申请点击“Create new secret key”
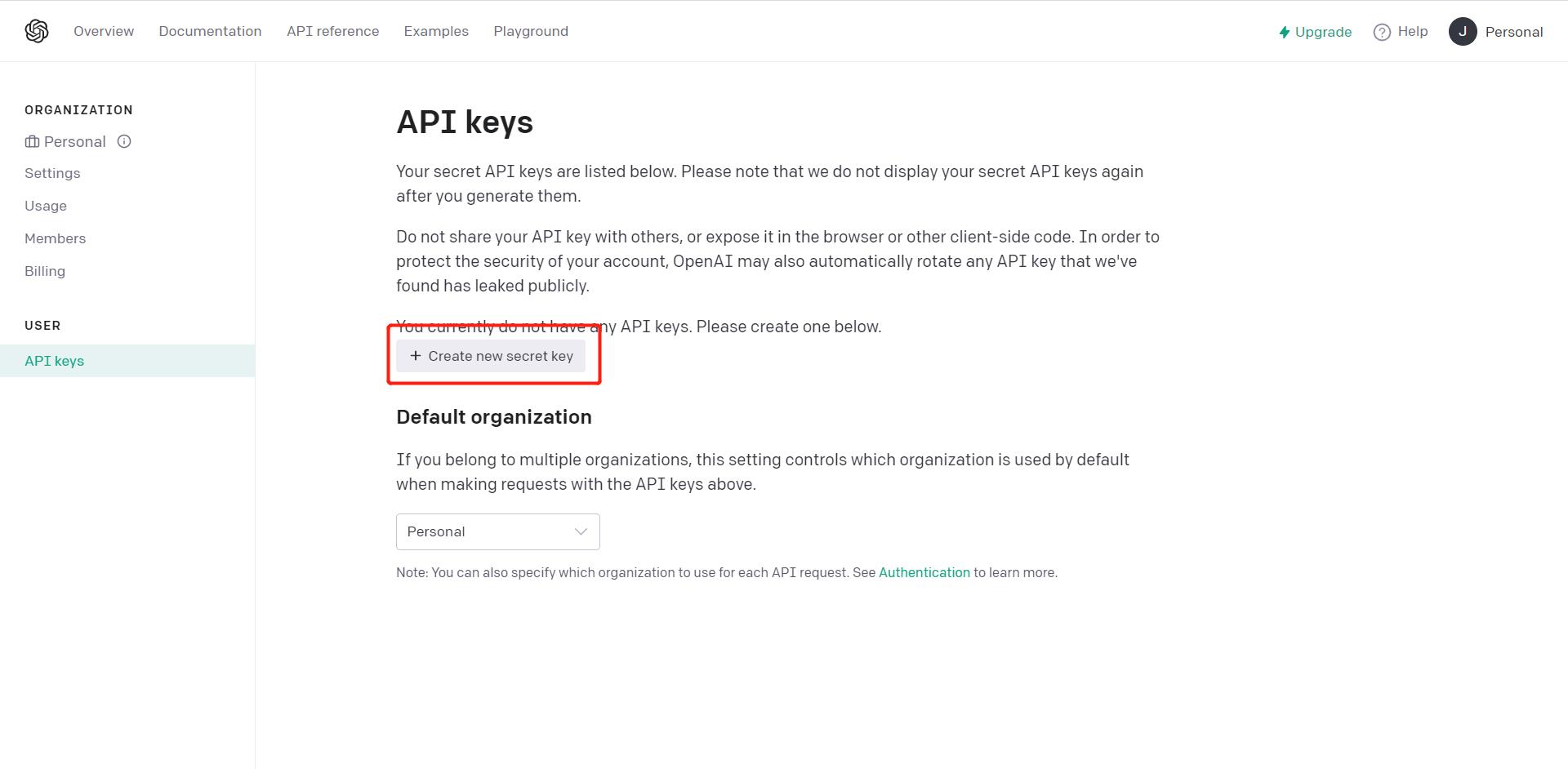
输入任意key名字
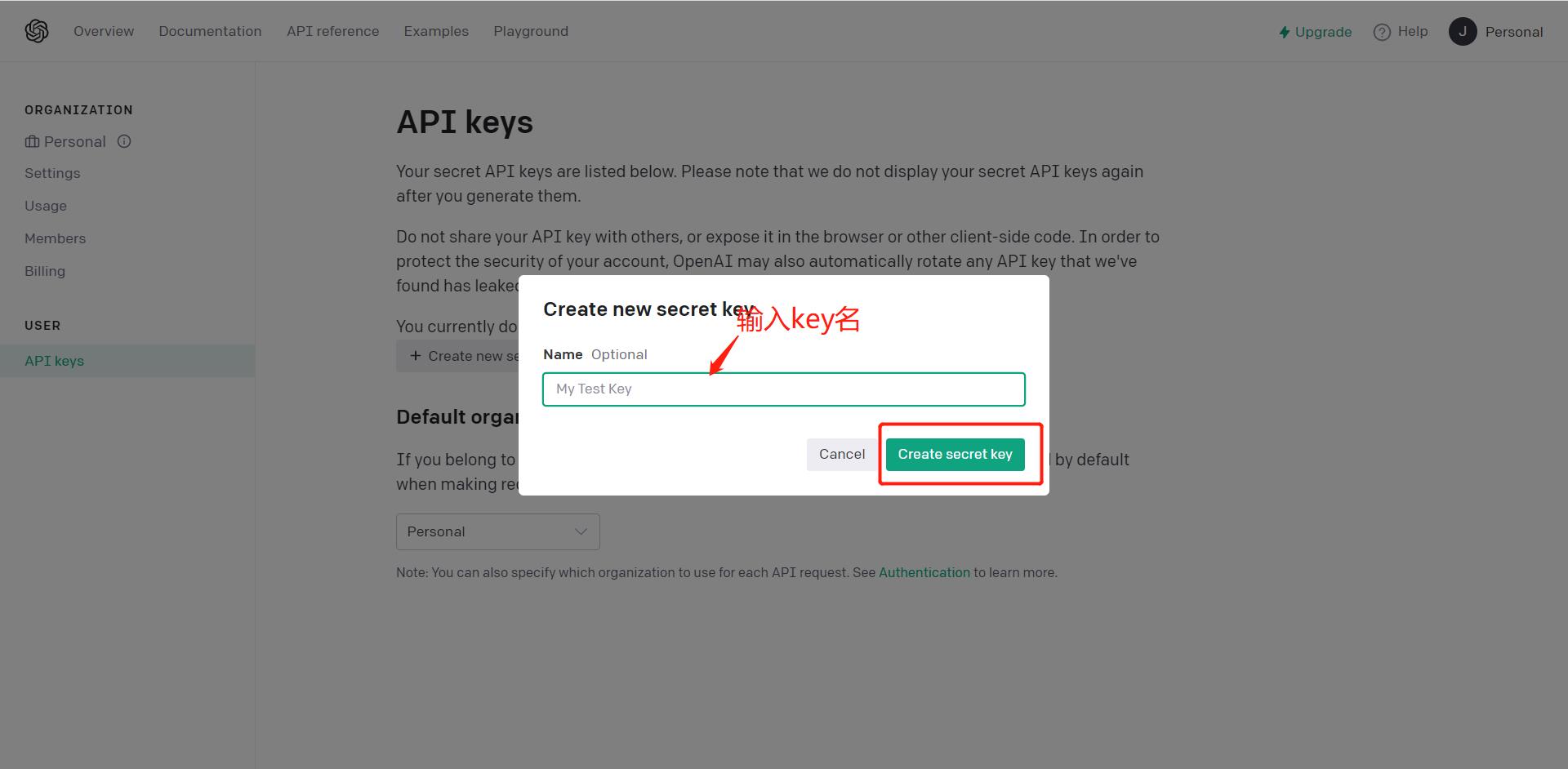
复制你的Secret Key,注意:这个Key只有在这可以复制,如果没保存就关掉对话框,需要重新生成一个新的key。
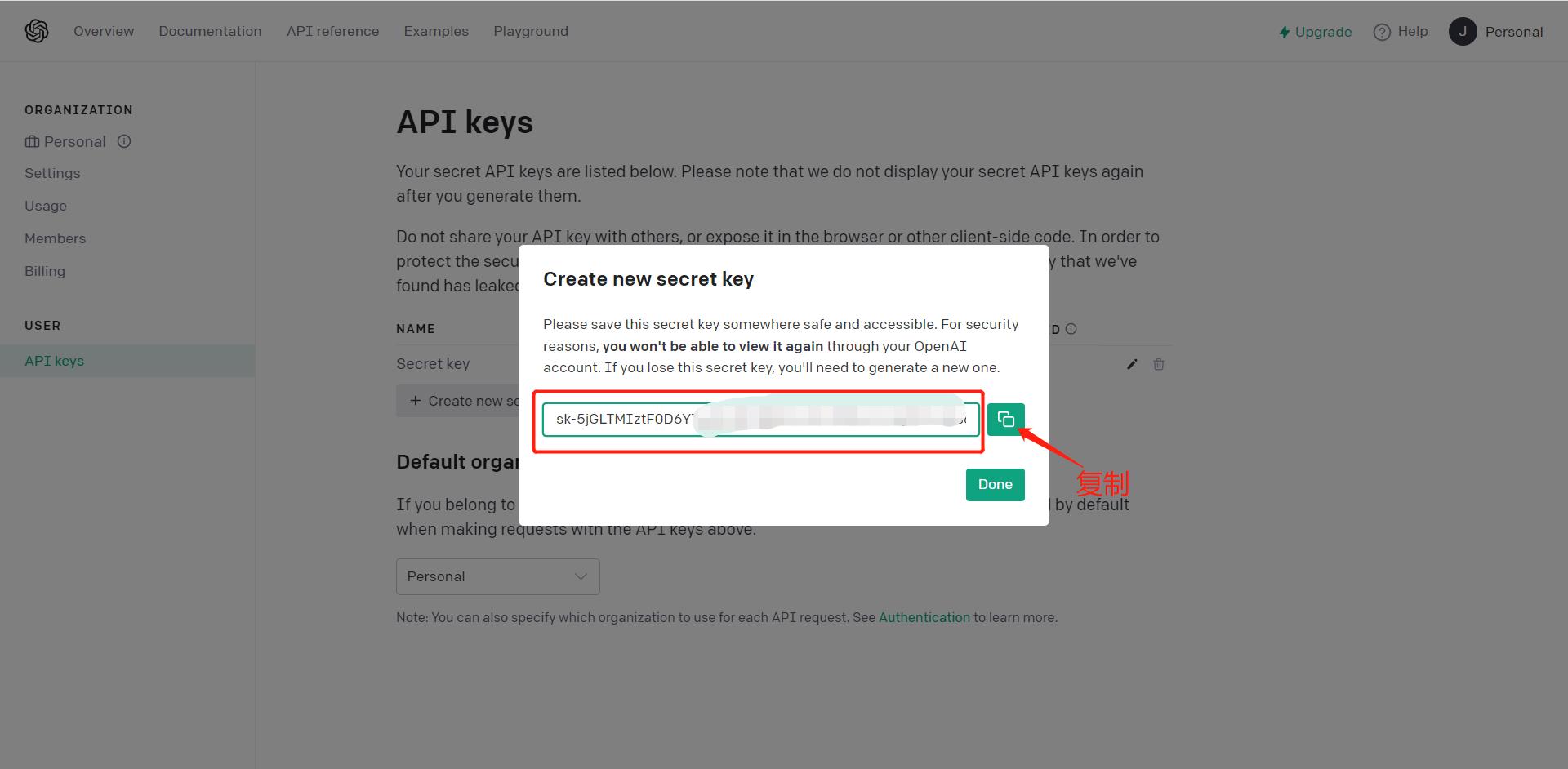
# 开发
pip安装openai
pip install openai
创建一个新的脚本helloai.py
import os
import openai
#填入你的OPENAI_API_KEY
openai.api_key = "OPENAI_API_KEY"
#代理设置:如果你在墙内需要使用代理才能调用,支持http代理和socks代理
#openai.proxy = "http://127.0.0.1:1080"
#这里我们使用的model是gpt-3.5-turbo
#使用角色为role,提问的内容是:Hello!
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "Hello!"}
]
)
#输出生成的内容
print(completion.choices[0].message)
#把整个响应输出一下
print(completion)
运行脚本python ./helloai.oy
返回output
Hello there, how may I assist you today?
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "\n\nHello there, how may I assist you today?",
},
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21
}
}
调用代码非常简单,下面大概讲解代码及openai.ChatCompletion.create的相关参数
# 代理问题
由于众所周知原因,OpenAI服务器已经被墙,直接运行大概率会遇到如下错误:
raise error.APIConnectionError(
openai.error.APIConnectionError: Error communicating with OpenAI: HTTPSConnectionPool(host='api.openai.com', port=443):
Max retries exceeded with url:/v1/chat/completionss (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x0000019B6187ABE0>:
Failed to establish a new connection:
[WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主 机没有反应,连接尝试失败。'))
解决有两种方案:
1)全局科学上网
2)增加代理设置,openai库支持设置http代理和socks代理
openai.proxy = "http://127.0.0.1:1080"
# model参数
model参数是指示API使用哪个训练模型生成对话,目前OpenAI的对话生成模型有:
gpt-4、gpt-4-0314、gpt-4-32k、gpt-4-32k-0314、gpt-3.5-turbo、gpt-3.5-turbo-0301
GPT-4模型说明
| 模型名称 | 描述 | 最大Token | 训练数据 |
|---|---|---|---|
| gpt-4 | 比任何 GPT-3.5 模型都更强大,能够执行更复杂的任务,并针对聊天进行了优化。将使用我们最新的模型迭代进行更新。 | 8,192 | 截至 2021 年 9 月 |
| gpt-4-0314 | 2023 年 3 月 14 日的gpt-4快照。与gpt-4不同的是,此模型不会收到更新,并且会在新版本发布后 3 个月后弃用。 | 8,192 | 截至 2021 年 9 月 |
| gpt-4-32k | 与基本gpt-4模式相同的功能,但上下文长度是其 4 倍。将使用我们最新的模型迭代进行更新。 | 32,768 | 截至 2021 年 9 月 |
| gpt-4-32k-0314 | 2023 年 3 月 14 日的gpt-4-32快照。与gpt-4-32k不同的是,此模型不会收到更新,并且会在新版本发布后 3 个月后弃用。 | 32,768 | 截至 2021 年 9 月 |
GPT-3.5模型说明
| 最新款 | 描述 | 最大token | 训练数据 |
|---|---|---|---|
| gpt-3.5-turbo | 功能最强大的 GPT-3.5 模型,并针对聊天进行了优化 | 4,096 | 截至 2021 年 9 月 |
| gpt-3.5-turbo-0301 | 2023 年 3 月 1 日的gpt-3.5-turbo快照。与gpt-3.5-turbo不同的是,此模型不会收到更新,并且会在新版本发布 3 个月后弃用。 | 4,096 | 截至 2021 年 9 月 |
# messages参数
messages参数是当前对话的列表。
messages=[{"role": "user", "content": "Hello!"}]
role有3种类型:system,user, assistant
system:系统角色也称为系统消息,包含在数组的开头。此消息向模型提供初始说明。您可以在系统角色中提供各种信息,包括:
- 助手简介
- 助理的人格特质
- 您希望助理遵守的指示或规则
- 模型所需的数据或信息,例如常见问题解答中的相关问题
user:用户提问的文本内容
assistant:ChatGPT返回的内容,用于多轮对话
由于模型不会存储你之前对话的内容,如果需要进行多轮对话,就需要把之前的完整对话和返回消息也放到messages参数里面,这样ChatGPT才能根据上下文来返回准确的消息。
举个例子帮助大家理解,问ChatGPT关于2022年世界杯的一系列问题
第一次调用,我们先设置ChatGPT为一个助理模式然后提问,messages参数为:
[{"role": "system", "content": "你是个好助理."},
{"role": "user", "content": "谁赢了2022年世界杯?"}]
ChatGPT生成的消息:
{"role": "assistant", "content": "阿根廷国家队赢得2022年世界杯"}
第二次调用,我们继续提问在哪举行,messages参数为:
[{"role": "system", "content": "你是个好助理."},
{"role": "user", "content": "谁赢了2022年世界杯?"},
{"role": "assistant", "content": "阿根廷国家队赢得2022年世界杯"},
{"role": "user", "content": "在哪里举办的?"}]
ChatGPT生成消息:
{"role": "assistant", "content": "2022年世界杯在卡塔尔举办"}
第三次调用,我们继续提问梅西进了多少球,messages参数为:
[{"role": "system", "content": "你是个好助理."},
{"role": "user", "content": "谁赢了2022年世界杯?"},
{"role": "assistant", "content": "阿根廷国家队赢得2022年世界杯"},
{"role": "user", "content": "在哪里举办的?"},
{"role": "assistant", "content": "2022年世界杯在卡塔尔举办"},
{"role": "user", "content": "梅西打进了多少个球?"}
]
ChatGPT生成消息
{"role": "assistant", "content": "梅西在2022年世界杯打进七球"}
可以看到如果需要保存上下文提问生成,就要把ChatGPT的返回也要放在messages中一起请求。
# Token的概念
OpenAI是根据对话和生成词量(Token)来计费的,提问的时候需要注意长度,不然很快消耗完配额
Token这个概念来源编译器,意思是词法分析后的标识符,OpenAI用Token来标注一段话内容关键内容。
如我们上面调用openAI后返回的其中usage参数:
"usage": {
"prompt_tokens": 9,//提问词hello的token数量
"completion_tokens": 12,//生成返回内容的token数量
"total_tokens": 21//总计消耗token数量
}
可通过max_tokens参数来控制生成返回的最大token,以免过度消耗
OpenAI官方的统计Token数量工具网站
https://platform.openai.com/tokenizer
# 完整示例
这是一个命令行交互式输入的示例,启动后输入问题,然后回车
import os
import openai
#填入你的OPENAI_API_KEY
openai.api_key = "OPENAI_API_KEY"
#代理设置:如果你在墙内需要使用代理才能调用,支持http代理和socks代理
#openai.proxy = "http://127.0.0.1:1080"
conversation=[{"role": "system", "content": "You are a helpful assistant."}]
while(True):
user_input = input()
conversation.append({"role": "user", "content": user_input})
response = openai.ChatCompletion.create(
engine="gpt-3.5-turbo", # 模型.
messages = conversation
)
conversation.append({"role": "assistant", "content": response['choices'][0]['message']['content']})
print("\n" + response['choices'][0]['message']['content'] + "\n")